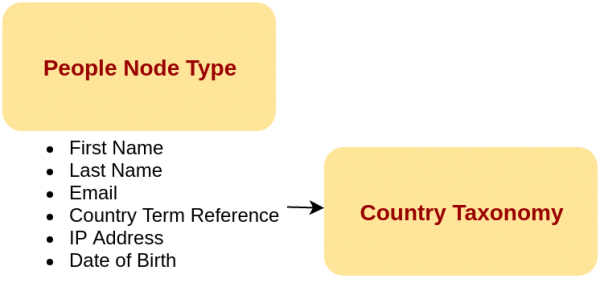
As the maintainer of the popular D8 Migrate Source CSV contrib module, it is about time I wrote how to use the thing. It is similar to a core migration, except you have to already create the destination node, taxonomies, etc. I'm going to use a simple example in this post of a person that is destined to land in a Person node type with a related Country taxonomy.
So, start by building out the People node type and its related taxonomy. Then come back and we'll continue with the CSV migration. OK, you're back now? Great. Let's dive into the migration.
Migrations in D8 follow a 3 step process. Gather the data, massage the data, then save the data into a destination.
- Gather = Source plugin
- Massage = Process plugin
- Save = Destination plugin
Thankfully, someone already wrote all these plugins for you. Some of these are in core and some are in various contrib modules. You just need to wire them up in a migration yml file.
The yml file looks like all other yml files in Drupal 8. So you (should be) familiar with it by now. If not, here's your chance to familiarize yourself with yml.
Here's a super simple source excerpt:
source:
plugin: csv
path: public://csv/people.csv
header_row_count: 1
keys:
- id
column_names:
0:
id: Identifier
1:
first_name: First Name
Here's a simple process excerpt
process:
type:
plugin: default_value
default_value: people
title: first_name
Here's the destination excerpt:
destination:
plugin: entity:node
Let's break each of those sections down further. The source section has a few moving parts. But its main purpose is to provide a list of all the names of things available from the source. For a CSV migration, you map the column number to a machine_name and a friendly name. Another purpose of the source is to provide a way to disambiguate one row of CSV from another, so you don't re-import the same thing multiple times. Lastly, we have to provide configuration to the CSV plugin so it can find and read the file.
- plugin: csv => The source plugin ID we want to use.
- path: public://csv/people.csv => Path to where the csv is located.
- header_row_count: 1 => How many lines to skip at the beginning of the CSV because they are considered the header row(s).
- keys => A yml array of column names that make the row unique, so you don't re-import the same thing multiple times.
- column_names => Numeric indexed yml array of column names.
- file_class, delimiter, enclosure, escape => Advanced configuration options that I won't go into. Read the schema definition for them in the migrate_source_csv module at
config/schema/migrate_source_csv.source.schema.yml
Next, the process section. This is where we spend most of our time, mapping data from the source to the destination. There are various process plugins already built for you in core and contrib. Combine them to massage your data into a format suitable for inserting into the destination.
Here's a more complete and slightly more complex process snippet:
process:
# The content (node) type we are creating is 'people'.
type:
plugin: default_value
default_value: people
# Most fields can be mapped directly - we just specify the destination (D8)
# field and the corresponding field name from above, and the values will be
# copied in.
title:
plugin: concat
source:
- first_name
- last_name
delimiter: ' '
field_first_name: first_name
field_last_name: last_name
field_email: email
field_country:
plugin: entity_generate
source: country
field_ip_address: ip_address
field_dob:
plugin: format_date
from_format: 'm/d/Y'
to_format: 'Y-m-d'
source: date_of_birth
For the values where there is a strait one-to-one mapping with no data massaging, we just have to map the values. If we cannot just map over the values, then we need to manipulate the data en-route from source to destination. If you are coming at this from D7, that's where you *would* have done a lot of php coding in prepareRow(). Well, you can still hook into that... but 98% of the time, you can wrangle the data with the available process plugins. Let's break down the more complicated process plugins above.
Default value: This does what you would think it does. It provides a default value. In our case, it sets the node bundle to 'people.
Concat: This also does what you'd think. It strings two or more values together with an optional delimiter.
Entity generate (migrate_plus): This one is fairly complicated under the hood. Keeping things simple, it lets you generate a taxonomy term (or any entity) if the entity does not exist. If it does exist, it just uses it. In either case, the return value from 'entity_generate' is an entity id for storing in an entity reference field. It does this by introspecting the entity reference destination field and running a database query to see if a term (or node) exists with the name/title provided from the source value. I'll hint that there is more power in this plugin, so read its doxygen and see what it and its sister 'entity_lookup' can do with various optional parameters.
Format date (migrate_plus): There aren't any date format process plugins in core, so I added one to migrate_plus for the purposes of this blog post. You pass this plugin the source format and the destination format and the rest is transformed by php's date functions. I briefly explored using the callback process plugin, but with that plugin, you cannot pass any extra arguments to it. So I built a contrib date format plugin.
The last part of a migration yaml is the destination. Plop a destination into the yml and you should be good to go.
Here's a full copy of an entire migrate yml file. And if you want to see all the code, I also have linked a full example project in the references. Look specifically at web/modules/custom/custom_migrate/config/install/migrate_plus.migration.migrate_csv.yml. The example was built with drupalvm. All you have to do to use it is run vagrant up && drush @d8-custom-migrate.dev mi --all
uuid: 5c12fdab-6767-485e-933c-fd17ed554b27
langcode: en
status: true
dependencies:
enforced:
# List here the name of the module that provided this migration if you want
# this config to be removed when that module is uninstalled.
module:
- custom_migrate
# The source data is in CSV files, so we use the 'csv' source plugin.
id: migrate_csv
label: CSV file migration
migration_tags:
- CSV
source:
plugin: csv
# Full path to the file.
path: /artifacts/people.csv
# The number of rows at the beginning which are not data.
header_row_count: 1
# These are the field names from the source file representing the key
# uniquely identifying each game - they will be stored in the migration
# map table as columns sourceid1, sourceid2, and sourceid3.
keys:
- id
# Here we identify the columns of interest in the source file. Each numeric
# key is the 0-based index of the column. For each column, the key below
# (e.g., "start_date") is the field name assigned to the data on import, to
# be used in field mappings below. The value is a user-friendly string for
# display by the migration UI.
column_names:
# So, here we're saying that the first field (index 0) on each line will
# be stored in the start_date field in the Row object during migration, and
# that name can be used to map the value below. "Date of game" will appear
# in the UI to describe this field.
0:
id: Identifier
1:
first_name: First Name
2:
last_name: Last Name
3:
email: Email Address
4:
country: Country
5:
ip_address: IP Address
6:
date_of_birth: Date of Birth
process:
# The content (node) type we are creating is 'people'.
type:
plugin: default_value
default_value: people
# Most fields can be mapped directly - we just specify the destination (D8)
# field and the corresponding field name from above, and the values will be
# copied in.
title:
plugin: concat
source:
- first_name
- last_name
delimiter: ' '
field_first_name: first_name
field_last_name: last_name
field_email: email
field_country:
plugin: entity_generate
source: country
field_ip_address: ip_address
field_dob:
plugin: format_date
from_format: 'm/d/Y'
to_format: 'Y-m-d'
source: date_of_birth
destination:
# Here we're saying that each row of data (line from the CSV file) will be
# used to create a node entity.
plugin: entity:node
# List any optional or required migration dependencies.
# Requried means that 100% of the content must be migrated
# Optional means that that the other dependency should be run first but if there
# are items from the dependant migration that were not successful, it will still
# run the migration.
migration_dependencies:
required: {}
optional: {}
Are you looking for help with a Drupal migration or upgrade? Regardless of the site or data complexity, MTech can help you move from a proprietary CMS or upgrade to the latest version–Drupal 8.
Write us about your project, and we’ll get back to you within 48 hours.